![[RSS]](../theme/image/rss.png)
ADQL Traps #1: NULL
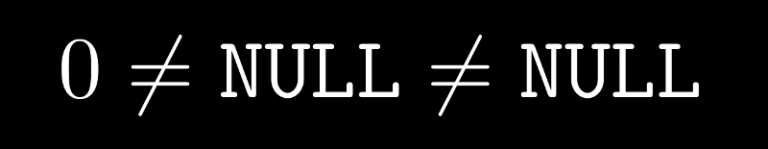
NULL is a difficult concept. Not only in SQL
I recently got embarrassed by ADQL NULLs, i.e., the magic value indicating that a value in a given column is missing. And since that's a common source of errors when writing ADQL queries, I'll take this as a cue for a blog post.
The concrete background is fairly technical and registry-ish; suffice it to say that some data providers who implemented interfaces conforming to some standard didn't properly say so in their registry records. Back in RegTAP 1.0 (that's the standard that says how a client like TOPCAT talks to the VO Registry), I decided to work around that by fudging the pattern for how to discover those interfaces so they'd still be found.
In RegTAP 1.1, which is now under review by the VO community, I wanted to do away with that workaround. But would that break anything? This question translates to “are there vs:ParamHTTP interfaces that don't have a role attribute of std”. Whatever “ParamHTTP” and “role attribute” actually mean, just appreciate that it looks like it might translate into SQL like:
select * from rr.interface where intf_type='vr:paramhttp' and not intf_role='std'
I ran that query, rejoiced because it didn't return anything, removed the workarund from the standard, and then was shot down when I read Mark's mail (politely) saying I'm wrong and there are services still requiring the workaround. As usual: If a query returns what you expect, be double careful.
What went wrong? Well, NULL semantics. You see, in SQL NULL is never equal to anything, not even itself (it's like NaN in IEEE floats in that: try n = float('nan');print(n==n) in Python and look again if you're cool about it). It's also not unequal. Don't take my word for it. Try:
select * from tap_schema.schemas where NULL=NULL
and:
select * from tap_schema.schemas where NULL!=NULL
– you'll get empty results in both cases.
What does that mean for science queries? Well, whenever there's NULLs in columns (and the only safe assumption for now is that they may hide in there; we should probably add nun-null as a column property in the tap schema and in VODataService some day), you need to be careful in particular with inverted logic.
Here's an example: Suppose you want to investigate NGC objects brighter than 10 mag in B in one bin in everything else in another. The ones brighter are simple:
select count(*) from openngc.data where mag_b<10
(try it on the TAP server at http://dc.g-vo.org/tap, it's 383 in the current release). It becomes difficult for “the rest”. If you write:
select count(*) from openngc.data where not mag_b<10
or, equivalently:
select count(*) from openngc.data where mag_b>=10
you'll get (for the current release) 10887. However, the whole catalogue has 13954 entries, so there's 13954-10887-383=2684 rows missing. Your “rest” has missed everything for which mag_b isn't given. Sure enough:
select count(*) from openngc.data where mag_b is null
(and this is the only good way to compare against null) gives 2684.
The right way to say “anything for which mag_b is not smaller than 10” thus is:
select count(*) from openngc.data where not mag_b<10 or mag_b is null
Morale: Unless you're sure there are no missing values (i.e., NULLs) in a column you're looking at, think about what these mean to your research (or other) question: Should these rows just vanish? Then you usually don't need to do anything and the SQL semantics magically do the right thing (which is why things are defined as they are). If, however, the corresponding rows would mean something to your question, you need to be explicit, and you must have some condition involving IS NULL or IS NOT NULL.
The trouble, of course, is that just knowing this still isn't enough. You need to remember it in the right moment. Or you'll share my fate of suffering some public embarrassement.